[24’] A Survey on Multimodal Large Language Models
카테고리: Multimodal
태그: Summary
1. Introduction
MLLM(Multimodal Large Language Model) 분야 공부의 첫 걸음으로 Survey 논문을 읽고 정리하였다. 정리한 내용을 바탕으로 근간이 되는 논문들을 선정하고 차근차근 읽어나갈 예정이다. 여기서는 키워드와 분류 위주로 정리하였다.
1.1. Background
최근 빠르게 발전하고 있는 LLM에는 emergent ability, 즉 창발적인 특성이 있다. Instruction following, In-Context Learning (ICL), Chain of Thought (CoT)와 같은 것들이 이에 해당한다. 이러한 특성은 LLM이 다양한 task를 수행할 수 있게 해주었다. 그러나 LLM은 vision input은 이해할 수 없다. 한편 LVM(Large Vision Model)은 vision input을 잘 이해하지만 reasoning에 제약이 있다. 따라서 MLLM은 LLM과 LVM의 장점을 결합하여 vision input을 이해하고 reasoning을 수행할 수 있는 모델을 만들어야 한다는 필요에 의해 탄생하였다.
MLLM 이전에도 multimodal model에 대한 여러 연구가 진행되었고, 크게 (1) discriminative models, (2) generative models로 나눌 수 있다.
- Discriminative Models
- [21’ ICML] CLIP: Learning transferable visual models from natural language supervision
- [21’ NIPS] ALBEF: Vision and Language Representation Learning with Momentum Distillation
- [20’ ECCV] Uniter: Universal image-text representation learning
- Generative Models
- [22’ ICML] OFA: Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework
- [21’ ICML] VL-T5: Unifying Vision-and-Language Tasks via Text Generation
- [21’] SimVLM: Simple Visual Language Model Pretraining with Weak Supervision
OFA로 대표되는 generative model과 MLLM은 모두 sequence-to-sequence 형식으로 multimodal 데이터를 처리한다는 공통점을 가지고 있다. 그러나 MLLM은 OFA와 달리 large-scale이며 multimodal instruction tuning과 같은 새로운 training paradigm을 사용한다.
- Multimodal Instruction Tuning
- [21’] FLAN: Finetuned Language Models Are Zero-Shot Learners
- [23’ NIPS] LLaVA: Visual instruction tuning
1.2. MLLM Timeline
초기 MLLM 연구는 text prompt + image / video / audio로부터 text content를 생성하는 컨셉의 연구가 주를 이루었다. 이후 연구는 이를 확장하면서 이루어졌다. (1) Granularity support, 즉 전체 image가 아닌 bounding box나 point 등도 인식할 수 있도록 하는 연구가 진행되었다. (2) Input 및 output modalities 확장 연구가 진행되었다. Image, video, audio, point cloud 등으로 확장되었다. (3) 더 다양한 language support를 지원하기 위한 연구가 진행되었다. (4) 더 많은 분야에 적용하기 위한 연구가 진행되었다. 예를 들면 medical domain으로 확장하거나, real world에서 사용하기 위한 연구가 진행되었다. 최근까지의 연구를 요약한 타임라인은 다음과 같다.
2. Architecture
MLLM은 크게 3가지의 module로 나눠볼 수 있다. (1) Pre-trained modality encoder, (2) pre-trained LLM, (3) modality interface이다. Modality interface는 (1)과 (2) 사이의 간극을 이어주는 역할을 한다. 필요에 따라 text가 아닌 output을 생성하기 위한 (4) optional generator가 추가될 수 있다.
2.1. Modality Encoder
Modality Encoder는 input modality를 LLM이 이해할 수 있는 형태로 변환하는 역할을 한다. 일반적인 VLM(Vision-Language Model)의 경우 CLIP과 같이 image-text alignment가 가능한 모델을 사용하며, 보통 pre-trained encoder를 그대로 사용한다.
Encoder를 선정할 때 고려할 수 있는 요소는 (1) resolution (2) parameter size (3) pretraining corpus 등이 있다. 여러 실험 결과 (1)은 성능에 큰 영향을 미치지만 (2)와 (3)은 그렇지 않다. 즉, input resolution이 높을수록 성능이 높아진다. 따라서 input resolution을 높이는 시도들이 진행되었고, 크게 (1) direct scaling과 (2) patch-division method로 나눌 수 있다.
- Direct Scaling: High-resolution input을 바로 encoder에 넣는 방식 (encoder 변경 필요)
- [23’] Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
- [23’] Improved LLaVA: Improved Baselines with Visual Instruction Tuning
- Patch-Division Method: High-resolution input을 patch로 나누어 encoder에 넣는 방식 (encoder 변경 불필요)
- [23’] Monkey: Image Resolution and Text Label Are Important Things for Large Multi-modal Models
- [23’] SPHINX: The Joint Mixing of Weights, Tasks, and Visual Embeddings for Multi-modal Large Language Models
- Experiments
- [24’] MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training
2.2. Pre-trained LLM
LLM 역시 pre-trained된 모델을 사용한다. 흔히 사용되는 public model은 다음과 같다.
이 중 Flan-T5 모델은 비교적 early LLM 모델로, BLIP-2나 InstructBLIP 등에서 사용되었다. LLaMA와 Vicuna 모델은 최근 대표적인 LLM 모델로 주목받고 있다. 이 외에도 계속 SOTA LLM 모델이 나오고 있기에 앞으로 등장하는 모델들로 계속 대체될 가능성이 높다.
- Flan-T5
- [22’] Flan-T5: Scaling Instruction-Finetuned Language Models
- [23’] BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
- [23’] InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning
- LLaMA and Vicuna
- [23’] LLaMA: Open and Efficient Foundation Language Models
- [23’] Llama 2: Open Foundation and Fine-Tuned Chat Models
- [23’] Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90% ChatGPT Quality
Modality encoder에서 input resolution이 높아짐에 따라 성능이 향상되었던 것과 같이 LLM에서도 parameter size가 성능에 큰 영향을 미친다. 또한 최근 MoE(Mixture of Experts)와 같은 모델이 주목받고 있다. 이러한 모델은 parameter 수를 늘리면서도 실제 computational cost는 늘리지 않기 때문에 효과적으로 성능을 향상시킬 수 있다. 이를 sparse architecture라고 부르기도 한다.
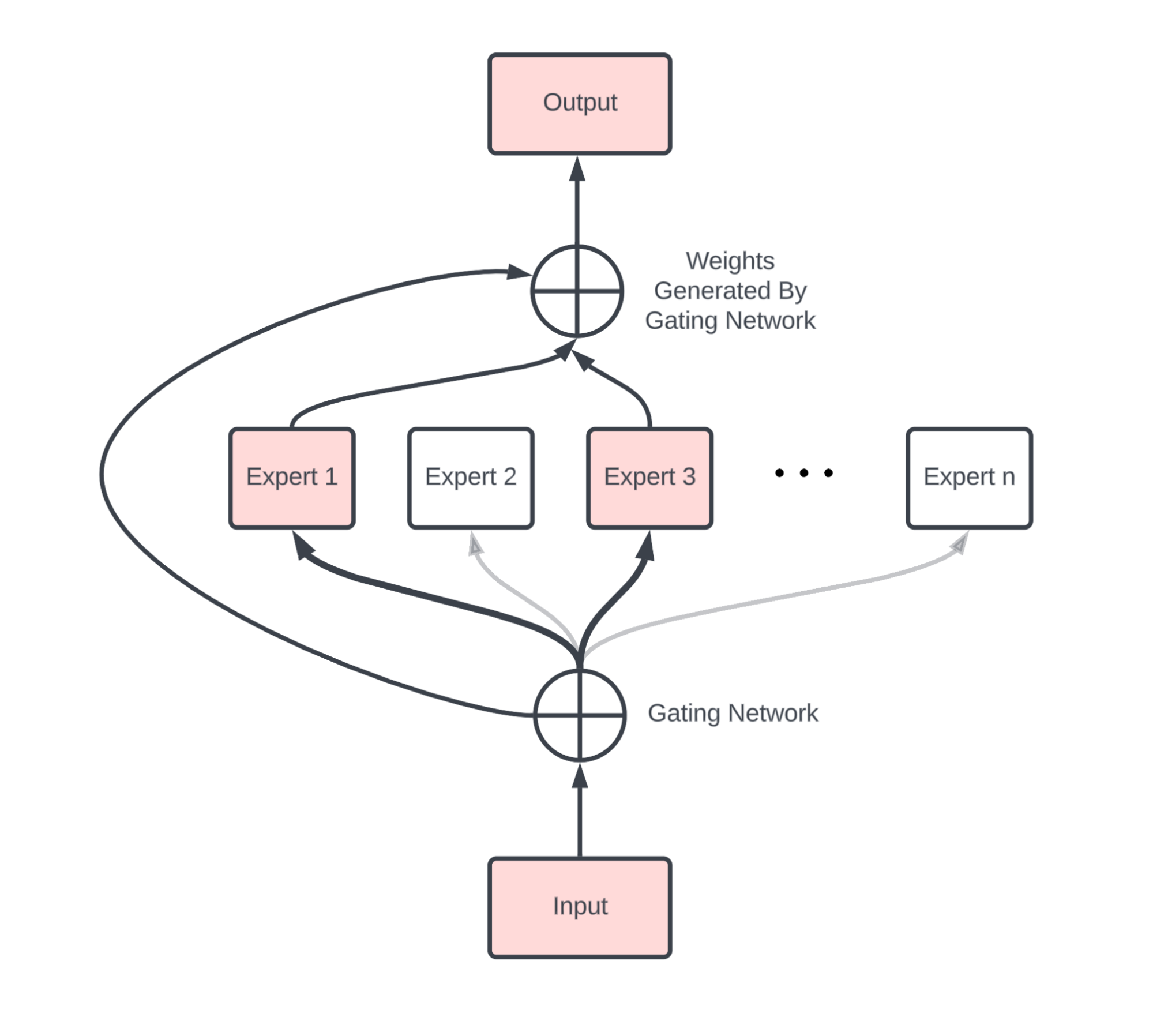
- Mixture of Experts
- [23’] FLAN-MOE: Mixture-of-Experts Meets Instruction Tuning:A Winning Combination for Large Language Models
- [24’] Mixtral 8x7B: Mixtral of Experts
- [24’] MoE-LLaVA: Mixture of Experts for Large Vision-Language Models
2.3. Modality Interface
Modality Interface는 (1) modality encoder와 (2) pre-trained LLM 사이의 간극을 이어주는 역할을 한다. 이와 같은 형태를 사용하는 이유는 multimodal model을 end-to-end로 학습하는 것이 굉장히 어렵고, 계산량이 많이 필요하기 때문이다. 보통 parameter size도 다른 두 개의 module에 비해 적다. Modality interface는 크게 (1) learnable connector와 (2) Expert model로 나누어 볼 수 있다. Learnable connector는 modality encoder의 output을 LLM의 input으로 변환할 수 있는 learnable model을 말하고, 크게 방법론에 따라 (a) Token-level fusion, (b) Feature-level fusion으로 나눌 수 있다. 이론적으로는 feature-level fusion이 더 깊은 interaction을 할 수 있지만, 실제로는 서로 장단점을 가지고 있다. 일반적으로 token-level fusion의 경우가 VQA에서 성능이 좋았지만 hyper-parameter searching이 더 어렵다고 한다. Expert model은 image captioning model과 같은 pre-trained model을 사용하여 natural language로 input을 변환하는 방법이다. 특히 learnable connector 부분을 분류해보면 다음과 같다.
- Learnable Connector
- Projection-based connector (MLP, token-level)
- [23’ NIPS] LLaVA: Visual instruction tuning
- [23’] Improved LLaVA: Improved Baselines with Visual Instruction Tuning
- Query-based connector (Q-Former, token-level)
- [20’] DETR: End-to-End Object Detection with Transformers (First introduced)
- [23’] BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
- Fusion-based connector (feature-level)
- [22’ NIPS] Flamingo: a Visual Language Model for Few-Shot Learning
- [23’] CogVLM: Visual Expert for Pretrained Language Models
- [23’] LLaMA-Adapter: Efficient Fine-tuning of Language Models with Zero-init Attention
- Projection-based connector (MLP, token-level)
3. Training Strategy and Data
MLLM의 training stage는 크게 3단계로 나누어 볼 수 있다. (1) Pre-training, (2) Instruction-tuning, (3) Alignment tuning이다. 각각의 내용을 간단히 요약해보면 다음과 같다.
- Pre-training: Large-scale text-paired data (e.g. caption data)를 사용하여 학습한다. Modality 간 alignment를 통해 전반적인 multimodal knowledge를 학습하는 것을 목표로 한다.
- Instruction-tuning: 가장 중요한 부분으로, 각종 instruction을 통해 학습하며 이를 통하여 필요로 하는 task-learning이 가능하고, zero-shot performance를 향상시킬 수 있다.
- Alignment-tuning: 일반적으로 hallucination을 줄이기 위하여 진행되며 human preference와 model output 간의 alignment를 높이기 위해 진행한다.
3.1. Pre-training
Pre-training은 다음과 같이 나타낼 수 있다. 이때 caption data와 같은 text-paired data를 사용한다.
많이 사용하는 방법은 visual encoder와 LLM은 frozen 상태로 두고 learnable interface만 학습시키는 것이다. 필요에 따라 visual encoder 등을 unfreeze하여 학습시키기도 한다.
한편 Data quality에 따라 학습 방법을 조절할 필요가 있다. Caption이 (1) short, noisy한 경우 lower resolution, (2) long, clean한 경우 higher resolution을 사용하는 것이 좋다. 이들을 각각 (1) Coarse-grained caption data, (2) Fine-grained caption data라고 부른다. 일반적으로 coarse-grained caption data는 인터넷의 alt-text를 이용하는 경우가 많고, fine-grained caption data는 GPT-4V와 같은 강력한 MLLM의 prompting을 통해 생성된 caption data를 사용하는 경우가 많다.
3.2. Instruction-tuning
Instruction-tuning은 여러 task에 대해 tuning을 진행하여 다양한 instruction에 대해 일반화 성능을 높이는 과정이다. 따라서 아래 그림과 같이 fine-tuning, prompting과는 다른 개념임을 알 수 있다. 특정한 task에 tuning하는 것이 아니라 unseen task에 대해서도 좋은 성능을 낼 수 있도록 하는 것이 목표이다.
Instruction tuning의 template는 목적에 따라 달라질 수 있으며 일반적으로 다음과 같이 나타낼 수 있다.
개념적으로 multimodal instruction sample을 $(\mathcal{I, M, R})$로 나타낼 수 있으며, 이때 $\mathcal{I}$는 instruction, $\mathcal{M}$은 multimodal input, $\mathcal{R}$은 ground truth response를 나타낸다. MLLM은 $\mathcal{I}$와 $\mathcal{M}$을 이용하여 결과 $\mathcal{A}$를 생성, 또는 예측한다.
\[\mathcal{A} = f(\mathcal{I}, \mathcal{M}; \theta)\]일반적으로 training objective는 LLM과 같은 auto-regressive 방식을 사용한다. 이때 $N$은 $\mathcal{R}$의 길이를 나타낸다.
\[\mathcal{L} (\theta) = - \sum_ {i=1} ^ {N} \log p(\mathcal{R}_ {i} | \mathcal{I}, \mathcal{R}_ {\lt i} ; \theta)\]Instruction tuning에 사용되는 data는 필요에 따라 달라지기 때문에, 일반적으로 pre-training에서 data를 모으는 것보다 어렵고 까다롭다. 따라서 일반적으로 (1) data adaptation, (2) self-instruction, (3) data mixture를 주로 사용한다. 요약하면 다음과 같다.
- Data Adaptation: VQA dataset, caption dataset과 같은 기존의 데이터셋을 사용한다.
- Self-Instruction: LLM을 이용하여 생성된 instruction을 사용한다.
- Data Mixture: language-only data와 multimodal data를 모두 사용한다.
Data adaptation의 장점은 데이터셋을 쉽게 얻을 수 있다는 것이다. 그러나 보통 이러한 데이터셋의 output은 굉장히 간단하기에, 이를 그대로 학습에 사용하는 경우 MLLM의 output length가 짧아지는 문제가 있다. 이를 해결하기 위해서 (1) 직접 instruction에 짧게 대답하라는 내용을 명시하거나, (2) 기존 데이터를 LLM을 사용하여 더 자세하게 늘려 사용하는 두 가지 방법이 흔히 사용된다.
Self-instruction에 의해 생성된 데이터셋도 최근에는 public dataset으로 사용되고 있다. 대표적인 것들은 위와 같다. 데이터의 수 뿐만 아니라 데이터의 퀄리티도 중요한데, prompt diversity를 늘리고 task coverage를 늘릴수록 성능이 좋아진다고 한다. 특히, captioning이나 VQA와 같은 단순한 task보다 visual reasoning과 같이 복잡한 task를 사용하고, task diversity를 늘리는 것보다 instruction complexity를 늘리는 것이 더 효과적이다.
지금까지의 내용의 주요 논문들을 정리하면 다음과 같다.
- Limitation of Data Adaptation
- [23’] ChatBridge: Bridging Modalities with Large Language Model as a Language Catalyst
- [23’] M3IT: A Large-Scale Dataset towards Multi-Modal Multilingual Instruction Tuning
- Self-Instruction
- [22’] Self-Instruct: Aligning Language Models with Self-Generated Instructions
- Experiments
- [23’] What Matters in Training a GPT4-Style Language Model with Multimodal Inputs?
- [23’] What Makes for Good Visual Instructions? Synthesizing Complex Visual Reasoning Instructions for Visual Instruction Tuning
3.3. Alignment-tuning
Alignment-tuning은 human preference와 model output 간의 alignment을 높이기 위해 진행한다. 이는 hallucination을 줄이기 위한 방법이다. 직관적으로 생각해볼 때, human evaluation을 통해 선호되는 방향으로 output을 생성하기 위한 방법이라고 할 수 있다. 흔히 (1) RLHF(Reinforcement Learning with Human Feedback), (2) DPO(Direct Preference Optimization)이 사용된다.
RLHF는 강화학습 알고리즘을 이용하는 방법으로, 크게 3단계로 나누어볼 수 있다.
- Supervised fine-tuning: Policy model $\pi^ \text{SFT}$를 학습한다. Instruction-tuned model을 그대로 사용할 수도 있다.
- Reward modeling: Reward model $r_ \theta (x, y)$를 학습한다. 이때 $x$는 multimodal input, $y$는 response output이다. 두 response pair $(y_ w, y_ l)$에 대하여 사람이 선호하는 response $y_ w$에 대해 높은 reward를 주고, 나머지 response $y_ l$에 대해 낮은 reward를 주도록 학습한다.
- Reinforcement learning: PPO(Proximal Policy Optimization) 등의 강화학습 알고리즘을 이용하여 $\pi^ \text{RL} _ \phi$를 학습한다. Original policy에서 너무 벗어나지 않도록 KL penalty를 사용한다.
Reward modeling, Reinforcement learning에서 사용되는 objective $\mathcal{L} (\theta)$, $\mathcal{L} (\phi)$는 다음과 같이 나타낼 수 있다.
\[\begin{aligned} \mathcal{L} (\theta) &= - \mathbb{E} _ {(x, y_ w, y_ l) \sim \mathcal{D}} \left[ \log \sigma (r_ \theta (x, y_ w) - r_ \theta (x, y_ l)) \right] \\ \mathcal{L} (\phi) &= - \mathbb{E} _ {x \sim \mathcal{D}, y \sim \pi^ \text{RL} _ \phi (y \vert x)} \left[ r_ \theta (x, y) - \beta \cdot \mathbb{D}_ {KL} \left( \pi^ \text{RL} _ \phi (y \vert x) \Vert \pi^ \text{SFT} (y \vert x) \right) \right] \end{aligned}\]DPO는 RLHF와 비슷하지만 reward model 대신 binary classification loss를 사용하는 방법이다. 이러한 방법을 preference learning이라고도 한다.
\[\mathcal{L} (\phi) = - \mathbb{E} _ {(x, y_ w, y_ l) \sim \mathcal{D}} \left[ \log \sigma \left( \beta \log \frac{\pi ^ \text{RL} _ \phi (y_ w \vert x)}{\pi ^ \text{REF} (y_ w \vert x)} - \beta \log \frac{\pi ^ \text{RL} _ \phi (y_ l \vert x)}{\pi ^ \text{REF} (y_ l \vert x)} \right) \right]\]데이터로는 아래와 같은 것들을 사용할 수 있다.
- RLHF
- [19’] RLHF: Fine-Tuning Language Models from Human Preferences
- [20’ NIPS] Learning to summarize from human feedback
- [23’] RLHF-LLaVA: Aligning Large Multimodal Models with Factually Augmented RLHF
- DPO
- [23’ NIPS] Direct Preference Optimization: Your Language Model is Secretly a Reward Model
4. Evaluation
Evaluation 방법은 크게 (1) Closed-set과 (2) Open-set으로 나뉜다. Closed-set은 가능한 답이 미리 몇 가지로 정해져 있는 경우이며, Open-set은 가능한 답이 미리 정해져 있지 않은 경우이다. 각각을 정리하면 다음과 같다.
- Closed-set: 비교적 명확하지만 task 및 dataset이 한정적이고, 종합적인 비교가 부족하다.
- Zero-shot setting: task를 held-in dataset과 held-out dataset으로 나누고, unseen task에 대해 성능을 평가한다. 더 일반적이다.
- Fine-tune setting: Domain-specific task에서 많이 사용한다.
- Open-set: 평가가 어렵지만 chatbot 등 MLLM의 일반적인 사용처에 적합한 평가 방법이다.
- Manual scoring: Human evaluation을 사용한다.
- GPT scoring: GPT-4V와 같은 benchmark의 scoring을 사용한다. GPT-4V가 upper bound가 될 수 있다는 문제가 있다.
- Case studies: 몇 가지 human-like task에 대해 분석하는 창의적인 방법이다.
5. Extensions
MLLM의 범위를 확장하기 위한 연구들을 크게 4가지, (1) Granularity support, (2) Modality support, (3) Language support, (4) Scenario/task extension으로 나눌 수 있다. 관련해서는 1.2. MLLM Timeline에서 언급하였으며, 여기서는 관련 논문들을 정리한다.
- Granularity Support
- [23’] Shikra: Unleashing Multimodal LLM’s Referential Dialogue Magic (Region Input)
- [23’] Osprey: Pixel Understanding with Visual Instruction Tuning (Pixel Input)
- [23’] Ferret: Refer and Ground Anything Anywhere at Any Granularity (Various Granularity)
- Modality Support
- [23’] LEO: An Embodied Generalist Agent in 3D World (3D Point Cloud Input)
- [23’] NExT-GPT: Any-to-Any Multimodal LLM (Any-to-Any)
- Language Support
- Scenario/Task Extension (Especially medical domain)
- [23’] LLaVA-Med: Training a Large Language-and-Vision Assistant for Biomedicine in One Day
- [23’ ML4H] Med-Flamingo: a Multimodal Medical Few-shot Learner
- [23’] PMC-VQA: Visual Instruction Tuning for Medical Visual Question Answering
6. Multimodal Hallucination
Multimodal hallucination이란 MLLM의 output이 image content와 일치하지 않을 때를 말하며, 개념적으로 3가지로 구분해볼 수 있다.
- Existence Hallucination: 존재성이 일치하지 않는 경우
- Attribute Hallucination: 속성이 일치하지 않는 경우 (색, 질감, 크기 등)
- Relationship Hallucination: Object 간 관계가 일치하지 않는 경우 (앞뒤 관계, 상호작용 등)
이러한 hallucination을 줄이기 위한 방법은 크게 (1) pre-correction, (2) process-correction, (3) post-correction으로 나누어 볼 수 있다. Pre-correction은 hallucination을 줄이기 위해 특정 데이터셋을 마련하는 방법, process-correction은 hallucination을 줄이기 위해 모델 디자인을 바꾸는 방법, post-correction은 hallucination을 줄이기 위해 모델의 output을 수정하는 방법이라고 할 수 있다.
- Pre-correction
- [24’ ICLR] LRV-Instruction: Mitigating Hallucination in Large Multi-Modal Models via Robust Instruction Tuning
- [23’] RLHF-LLaVA: Aligning Large Multimodal Models with Factually Augmented RLHF
- Process-correction
- [23’] HallE-Switch: Rethinking and Controlling Object Existence Hallucinations in Large Vision-Language Models for Detailed Caption
- [24’ CVPR] VCD: Mitigating Object Hallucinations in Large Vision-Language Models through Visual Contrastive Decoding
- [23’] HACL: Hallucination Augmented Contrastive Learning for Multimodal Large Language Model
- Post-correction
- [23’] Woodpecker: Hallucination Correction for Multimodal Large Language Models
- [23’] LURE: Analyzing and Mitigating Object Hallucination in Large Vision-Language Models
7. Extended Techniques
MLLM의 성능을 향상시키기 위한 여러 기술들, 또는 이를 활용한 사례들이 있다. 최근 활발하게 연구되는 분야로 (1) Multimodal ICL (M-ICL), (2) Multimodal CoT (M-CoT), 그리고 (3) LLM-Aided Visual Reasoning (LAVR)을 소개한다.
- Multimodal In-Context Learning (M-ICL): 일반적인 supervised learning이 data로부터 implicit pattern을 학습하는 것이라면, ICL은 analogy로부터 explicit pattern을 학습하는 것이다. ICL은 일반적으로 training-free이기 때문에 굉장히 가볍게 구현될 수 있다. 일반적인 M-ICL은 위와 같이 정리할 수 있으며, 일반적으로 demonstration 순서와 같은 것들에 굉장히 민감하다.
- [23’] A Survey on In-context Learning (Introduction)
- [23’] MIMIC-IT: Multi-Modal In-Context Instruction Tuning
- [24’ ICLR] Emu: Generative Pretraining in Multimodality
- Multimodal Chain of Thought (M-CoT): CoT은 sequential reasoning을 위한 방법론으로, intermediate reasoning step을 거쳐 성능을 향상시키고 더 복잡한 task를 수행할 수 있게 하는 것을 말한다.
- [22’] Chain-of-Thought Prompting Elicits Reasoning in Large Language Models (Introduction)
- [23’] Visual Chain of Thought: Bridging Logical Gaps with Multimodal Infillings
- [23’] Multimodal Chain-of-Thought Reasoning in Language Models
- [23’] Chain of Thought Prompt Tuning in Vision Language Models
- LLM-Aided Visual Reasoning (LAVR): LAVR은 LLM을 이용하여 visual reasoning을 수행하는 방법론이다. 일반적으로 LLM이 LVM보다 reasoning 성능이 뛰어나기 때문에, vision task를 language task로 전환하여 푸는 아이디어라고 직관적으로 생각하면 된다.
- [23’] MM-REACT: Prompting ChatGPT for Multimodal Reasoning and Action
- [23’] Caption Anything(CAT): Interactive Image Description with Diverse Multimodal Controls
8. Challenges and Future Directions
MLLM 연구는 아직 완벽하지 않고, 여러 가지 연구해야 할 문제들이 남아 있다.
- Long-context information을 잘 처리할 수 없다.
- Complicate instruction을 잘 처리할 수 없다.
- M-ICL과 M-CoT 관련 연구가 필요하다.
- MLLM에 기반한 embodied agent 개발 관련 연구, 즉 real-world 연구가 각광받고 있다.
- Safety issue에 대해 연구가 필요하다.
💡 Summary
MLLM은 multimodal data를 처리하는 방법론 중 하나로, (1) Pre-trained modality encoder, (2) pre-trained LLM, (3) modality interface로 구성된다. 이를 통해 multimodal data를 처리하며, (1) Pre-training, (2) Instruction-tuning, (3) Alignment-tuning을 통해 학습된다. 그 후 (1) Closed-set과 (2) Open-set으로 나누어 평가된다. 최근에는 (1) Multimodal ICL (M-ICL), (2) Multimodal CoT (M-CoT), 그리고 (3) LLM-Aided Visual Reasoning (LAVR)이 주목받고 있다.
댓글 남기기