[24’] MMStar: Are We on the Right Way for Evaluating Large Vision-Language Models?
카테고리: Multimodal
🔍 Abstract
저자들은 VLM Evaluation Dataset에서 치명적인 문제 두 가지를 발견한다. (1) 첫째는 많은 샘플에서 Visual Content 없이도 답을 얻을 수 있다는 점이고, (2) 둘째는 LLM 및 LVLM 학습 시 data leakage가 발생하여 답을 외워서 푸는 경우가 있다는 점이다. 이 두 가지 모두 VLM Evaluation을 부정확하게 만드는 요인이다. 따라서 이러한 것들을 제거한 MMStar라는 새로운 Benchmark를 제안한다.
1. Two Overlooked Issues for Evaluating LVLMs
🔍 Abstract에서 언급한 것과 같이 VLM Evaluation에는 2가지 문제가 있다. 이를 각각 다음과 같은 방법으로 평가하였다.
- Visual Content 없이도 답을 얻을 수 있는 경우: 이를 확인하기 위해 VLM Evaluation Dataset을 LLM이 풀도록 하였다. 결론적으로 많은 샘플에서 Visual Content 없이도 답을 얻을 수 있었는데, 그 이유를 분석해보면 크게 3가지로 나뉜다.
- Text-based Knowledge만으로도 답을 얻을 수 있는 경우 (Fig 1(a))
- 문제 자체에 정답이 있는 경우 (Fig 1(b))
- LLM Training data leakage로 인해 답을 외워서 푸는 경우 (Fig 1(c))
- VLM이 Data Leakage로 인해 답을 외워서 푸는 경우: 이를 확인하기 위해 LLM은 맞추지 못하지만, LVLM에서 Visual Content를 제거한 $\text{LVLM}^ {\text{Text}}$는 맞출 수 있는 경우를 확인하였다. 그 결과, Visual Content가 없는 경우에도 답을 맞출 수 있는 경우가 많았다. 즉, VLM 학습 도중에 data leakage가 일어나 답을 외워서 푼다는 것이 확인된 것이다. (Fig 1(d))
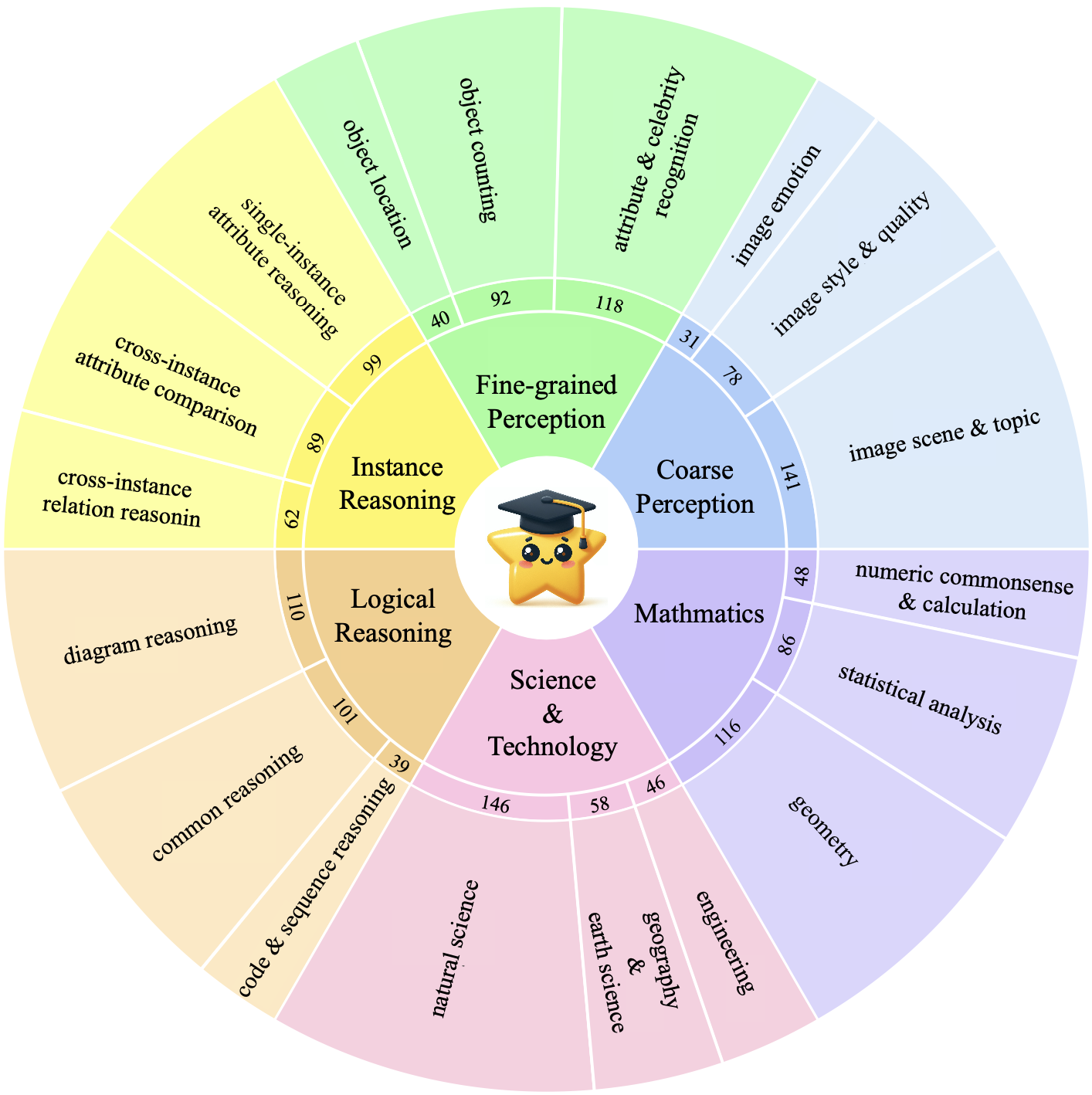
2. MMStar Benchmark
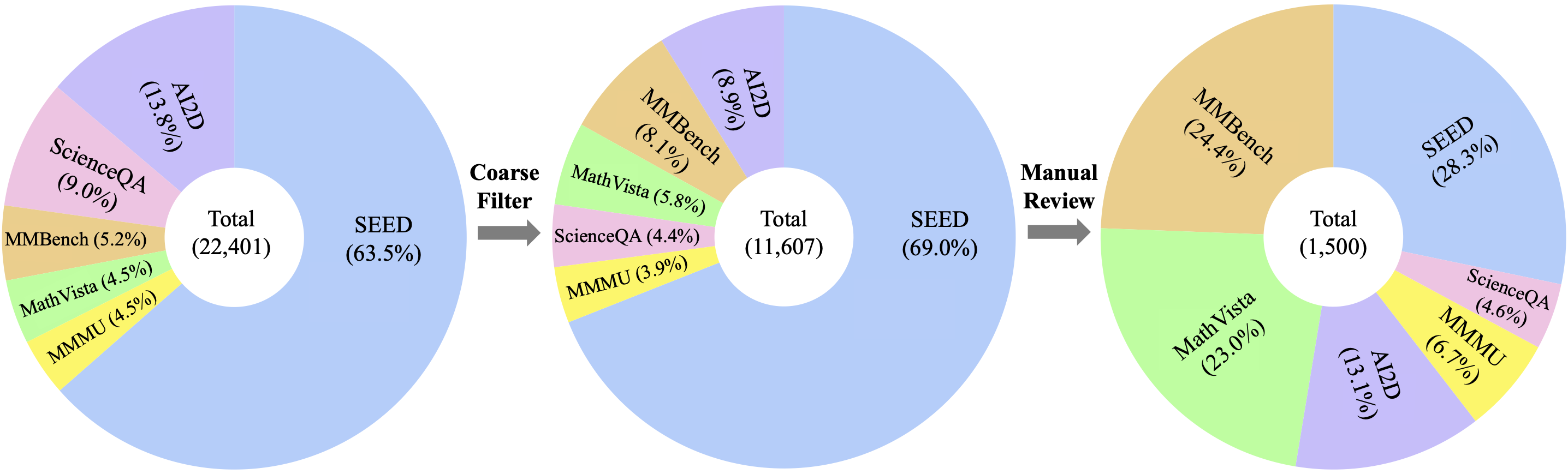
저자들은 따라서 coarse filter process와 manual review를 통해 22,401개의 샘플을 11,607개의 샘플로 줄이고, 이 중에서 high-quality sample 1,500개를 골라 MMStar라는 새로운 Benchmark를 제안한다. 이들로 기존 VLM을 평가한 결과는 다음과 같다.
역시 GPT-4V가 가장 좋은 결과를 보였고, Open-source 중에서는 LLaVA-NeXT가 가장 좋은 결과를 보였다.
💡 Summary
기존 VLM Evaluation Dataset의 Quality 및 Data Leakage 문제를 잘 포착하여 개선한 논문이다. 이 논문을 통하여 기존 VLM Evaluation의 부정확성을 인지할 수 있어서 유용했다.
댓글 남기기