[24’] xGen-MM (BLIP-3): A Family of Open Large Multimodal Models
카테고리: Multimodal
🔍 Abstract
- Problem & Method: 저자들은 BLIP-2의 3가지 문제점을 지적하고, 이를 해결한다.
- Data: BLIP-2는 적고 단순한 데이터셋을 사용했다. 저자들은 학습 데이터의 크기와 다양성을 늘려 성능을 향상시킨다. 특히 주목할 점은 Interleaved Dataset을 사용하여 Multi-Image Input을 제공한다는 점이다.
- Architecture: BLIP-2는 복잡한 Q-Former를 사용하지 않고 Flamingo와 같은 Visual Token Sampler 즉 Perceiver를 사용한다. 이는 보다 scalable하다. 추가로, High-resolution Image의 정보를 최대한 보존하기 위해 Any-Resolution Visual Token Sampling을 사용하는데, 자세한 내용은 이후에 다룬다.
- Training: BLIP-2는 3개의 Objective, 즉 ITC, ITG, ITM을 사용해야 했다. 저자들은 단순한 Next-token Prediction으로 학습 목표를 간단하게 만든다.
- Result
- 5B 정도의 굉장히 경량화된 모델로 유사한 Model Parameter를 가진 다른 모델들보다 우수한 성능을 보인다.
- 특히, Multimodal Few-shot Learning에서 뛰어난 성능을 보인다. 이는 BLIP-2에서 달성하지 못했던 성과이다.
xGen-MM (BLIP-3) 논문은 굉장히 상세한 내용을 담고 있다. 충분히 학습을 재현할 수 있을 정도로 작성하는 것을 목표로 둔 것으로 보인다. 따라서, 모든 내용을 리뷰하기보다는 논문의 내용 중에서도 특히 Architecture 부분을 중점적으로 다루고자 한다.
1. Architecture
xGen-MM (BLIP-3)의 Architecture에서 주목할 만한 부분은 두 가지인데, (1) Perceiver와 (2) Any-Resolution Visual Token Sampling이다.
1.1. Perceiver
Visual Token Sampler, 즉 Perceiver는 Flamingo와 같은 모델에서 사용한 방법이다. BLIP 계열의 모델이 더 이상 Q-Former를 사용하지 않는 점이 놀랍지만, 어쨌든 Query를 사용하여 정보를 추출하고 LLaVA와 같은 모델보다 Image Token을 덜 사용하여 효율적이라는 점에서는 비슷하다.
1.2. Any-Resolution Visual Token Sampling
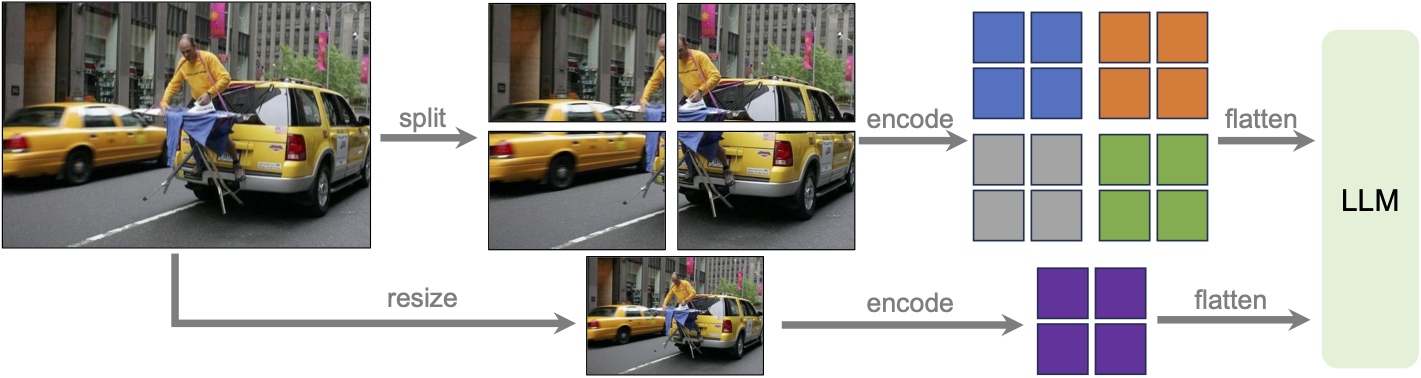
Any-Resolution Visual Token Sampling은 High-resolution Image의 정보를 최대한 보존하기 위한 방법이다. 즉, 일반적인 High-Resolution Image를 Patch로 나누어 Encoding하는 방식을 사용하며, 이때 특이한 점은 이렇게 얻은 Patch Embedding마다 Token Sampler를 적용한다는 점이다. 따라서, 이미지의 크기에 따라 Visual Token의 수가 달라질 수 있는 일종의 Dynamic Encoding Strategy라 볼 수 있다. 추가로 전체 이미지를 Downsizing한 하나의 Global Image도 포함한다.
2. Method
Training 과정은 크게 4단계로 나뉜다.
- Pre-training (xGen-MM-base): 일반적인 LMM Pre-training과 동일하다. 위와 같은 데이터들을 사용하였다. 이후 Few-shot 성능을 측정한다.
- SFT (xGen-MM-inst.): Pre-training된 모델을 Instruction Following을 위해 Fine-tuning한다.
- Interleaved Multi-Image SFT (xGen-MM-inst.-interleave): Multi-Image Input을 사용하여 Fine-tuning한다. SFT의 다음 과정으로 진행된다. 이들은 일반적인 LMM Benchmark에서 성능을 측정한다.
- Post-training (xGen-MM-inst. + DPO): LoRA DPO 학습으로 Human Alignment를 진행한다. Safety, Hallucination 등을 측정한다.
3. Experiments
3.1. Main Results
위에서 언급한 것과 같이 각 학습 과정에 대한 성능을 다음과 같이 측정하였다.
Pre-training
SFT
Post-training
3.2. Ablation Study
Pre-training
Visual Backbone. SIGLIP과 같이 Text-aligned Image Encoder를 사용할 때 OCR 성능이 향상되었다.
Visual Token. Perceiver의 Visual Token 수를 64로 하는 것과 128로 하는 것의 큰 차이가 없었다. 즉 Image Token의 Redundancy를 보여주며 충분히 Image를 적은 Token으로 줄일 수 있다는 것을 보여준다.
SFT
Any-Resolution Visual Token Sampling. Fixed Resolution을 사용하거나, Patch를 모두 하나의 Sequence로 모아 고정된 수의 Token을 사용하는 것이 성능이 떨어진다. 이는 Dynamic Token Sampling이 중요하다는 것을 보여준다.
Instruction-Aware Visual Token Sampling. InstructBLIP에서는 Instruction-aware Q-Former를 사용하여 성능을 향상시켰다. 저자들은 이것이 Perceiver와 같은 구조에도 적용되는지 보았다. 그러나 어떠한 성능 향상을 찾을 수 없었고, Instruction-Aware Perceiver의 경우 추가 연구가 필요하다고 덧붙였다.
💡 Summary
해당 논문의 내용을 간단히 요약하면 다음과 같다.
- xGen-MM은 BLIP-2의 문제점을 (1) 데이터의 크기와 다양성, (2) Architecture의 Scalability, (3) Training Objective의 단순화를 통해 해결함
- Q-Former가 아닌 Perceiver를 사용하고, High-resolution Image의 정보를 보존하기 위해 Any-Resolution Visual Token Sampling을 사용하였으며, Interleaved Dataset을 사용하여 Multi-Image Input을 제공함
댓글 남기기