[CS285] 10. Optimal Control and Planning
카테고리: CS285
태그: RL
💡 이 글은 『2024 PseudoLab 전반기 강화학습팀』으로 진행되었으며, CS285 Fall 2023를 따라 정리했습니다.
1. Model-based RL
1.1. Model-free vs. Model-based RL
지금까지 많은 model-free RL 알고리즘들을 배워 왔다. Model-free RL이란 environment의 dynamics를 모르는 상태에서 trial-and-error를 통해 optimal policy를 찾는 방법이다. 즉 state, action sequence를 다음과 같이 나타낼 때
\[p_ \theta (s_{1:T}, a_{1:T}) = p(s_1) \prod _ {t=1} ^ T \pi _ \theta (a_t \vert s_t) p(s_{t+1} \vert s_t, a_t)\]이 중 dynamic $p(s_{t+1} \vert s_t, a_t)$를 모르는 상태에서 policy를 optimize하는 것이다. 그러나 게임, 시뮬레이션 상황, 모델링이 간단한 상황 등에서는 이러한 transition dynamics를 알거나 어느 정도 학습할 수 있고, 이러한 경우에 사용할 수 있는 것이 model-based RL이다. Model-based RL은 environment의 dynamics를 모델링하고, 이를 이용하여 optimal policy를 찾는 방법이다. Model-based RL은 model-free setting에서는 사용할 수 없었던 강력한 알고리즘들을 사용할 수 있는 경우가 있기에 중요하다. 여기에서의 “model”은 딥러닝 모델이 아니라 상황을 모델링할 때의 모델을 의미한다. 정리하면 다음과 같다.
- Model-free RL: environment의 dynamics를 모르는 상태에서 sampling를 통해 optimal policy를 찾는 방법
- Model-based RL: environment의 dynamics를 모델링하고, 이를 이용하여 optimal policy를 찾는 방법
1.2. Open-loop vs. Closed-loop Planning
이러한 model-based RL은 planning이라는 개념과 연결된다. Planning은 model을 사용하여 simulation을 통해 optimal state-action $(s_t, a_t)$ sequence를 찾는 과정이라고 이해할 수 있다. 크게 open-loop planning과 closed-loop planning으로 나뉜다.
Open-loop planning은 first state $s_1$을 아는 경우 agent가 $a_1$부터 $a_T$까지의 action을 계획(planning)하는 것을 의미한다. 그러나 open-loop planning은 dynamics model이 deterministic한 경우에만 잘 들어맞는다. 예를 들어 다음과 같이 포켓몬으로 전투를 하는 agent를 생각해보자.

Open-loop training은 마치 “또가스”라는 포켓몬과 싸운다는 정보만 가지고 최적의 기술 조합을 찾는 것과 같다. 단순하게 생각해보면 그렇게 기술을 정하는 것이 어렵지는 않다. 더 정확하게 말하면 상대가 내 공격에 어떻게 반응할지 정확히 아는 상황, 즉 deterministic한 상황에서는 쉽다. 하지만 만약 중간에 상대방이 포켓몬을 다른 것으로 바꾼다면? 특수한 공격만 회피하는 기술을 사용한다면? 이러한 상황에서는 open-loop planning은 잘 들어맞지 않는다.
Closed-loop planning은 이러한 문제를 해결하기 위해 나왔다. Closed-loop planning은 agent가 state $s_t$를 알고 있을 때 action $a_t$를 계획하는 것을 의미한다. 즉, agent가 state $s_t$를 알고 있을 때 action $a_t$를 계획하고, 이를 통해 다음 state $s_{t+1}$을 알 수 있다. 이러한 방식은 dynamics model이 stochastic한 경우에 잘 들어맞는다. 정리하면 다음과 같다.
- Open-loop planning: agent가 first state $s_1$만 알고 있을 때 action $a_1$부터 $a_T$까지 계획, 따라서 deterministic dynamics model에 적합
- Closed-loop planning: agent가 state $s_t$를 알고 있을 때 action $a_t$를 계획, 이를 통해 다음 state $s_{t+1}$를 얻어 반복, 따라서 stochastic dynamics model에 적합
2. Stochastic Optimization
그럼 이제 이러한 planning의 몇 가지 중요한 방법론들을 알아보자. 가장 간단한 것은 stochastic optimization으로, open-loop planning에 속한다. Stochastic optimization은 blackbox optimization으로 불리기도 하는데, 이는 objective function이 정확히 어떤 함수인지 알지 못해도 사용할 수 있기 때문이다. Gradient를 사용하지 않기 때문에 gradient-free optimization이라고도 불린다.
먼저 objective function을 $J$, 정하고자 하는 action sequence $\mathbf{A} = (a_1, a_2, \cdots, a_T)$를 정의하자. 이때 구하고자 하는 것은 다음과 같이 나타낼 수 있다.
\[\mathbf{A}^ \ast = \arg \max _ {\mathbf{A}} J(\mathbf{A})\]
가장 간단한 방법은 uniform distribution과 같은 분포에서 $\mathbf{A}_ 1, \mathbf{A}_ 2, \cdots, \mathbf{A}_ N$을 샘플링하고, 각각 $J(\mathbf{A}_ 1), J(\mathbf{A}_ 2), \cdots, J(\mathbf{A}_ N)$을 계산한 후 가장 큰 값을 선택하는 것이다. 이러한 방법은 random shooting method라고 불린다.
조금 더 좋은 방법은 그 중에서도 좋은 $\mathbf{A}$들 위주로 distribution을 계속 update하여 좋은 action sequence가 뽑힐 확률을 높이는 것이다. 이러한 방법은 cross-entropy method(CEM)라고 불린다.
이러한 방법들은 굉장히 간단하고 병렬화(parallelization)하기 쉽다는 장점이 있다. 그러나 action sequence의 차원(dimensionality)이 커지면 이러한 샘플링이 어렵고, closed-loop planning에서는 사용할 수 없다는 단점이 있다.
3. Monte Carlo Tree Search (MCTS)
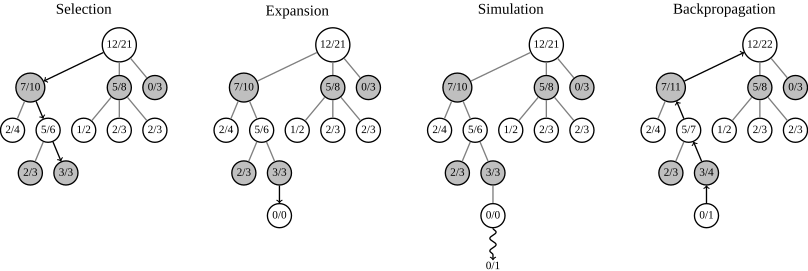
그렇다면 closed-loop planning에서 사용할 수 있는 Monte Carlo Tree Search (MCTS)에 대해 알아보자. MCTS 알고리즘은 현 상태 $s_1$에서 할 행동 $a_1$을 선택하기 위하여 가능한 행동 $a_1$에 대한 $Q(s_1, a_1)$을 통계적으로 계산하고, 이를 통해 $a_1$을 선택하는 방법이다. 알파고(AlphaGo)에서 사용된 알고리즘이기도 하다.
MCTS 알고리즘은 다음과 같은 과정을 거친다.
이 과정을 조금 더 직관적으로 나타내면 다음과 같다.

각 과정을 간단히 알아보자.
- TreePolicy는 Selection, Expansion 부분에 해당하며 score를 계산할 leaf node $s_l$을 선택 또는 확장하는 과정이다.
- DefaultPolicy는 Simulation 부분에 해당하며, leaf node $s_l$에서부터 간단한 policy를 따라 simulation을 진행하여 reward를 계산하는 과정이다.
- Backpropagation은 이를 통해 얻은 reward를 이용하여 각 node의 score를 업데이트하는 과정이다.
각 과정을 조금 더 자세히 알아보자. 먼저 TreePolicy는 주로 UCT(upper confidence bound for trees)를 사용한다. 알고리즘은 다음과 같다.
즉, TreePolicy는 simulation을 시행할 leaf node를 결정하는 알고리즘인데, 만약 $s_t$에서 아직 시행하지 않은 action $a_t$가 있다면 먼저 이를 시도하고, 그렇지 않다면(즉, 모든 action을 시행했다면) UCT를 이용하여 다음 leaf node를 선택한다. UCT는 sampling한 값들로부터 얻은 confidence interval의 upper bound이다. 따라서 score 값은 일종의 평균 $Q(s_t)/N(s_t)$과 표준편차 $2C \sqrt{\frac{2 \log N(s_{t-1})}{N(s_t)}}$의 합으로 나타내는 것이다. 각각을 해석해보면 평균값이 높을수록 좋은 $s_t$일 가능성이 높고, 따라서 이 $s_t$의 점수를 높인다. 한편 표준편차가 높을수록 이 $s_t$에 대한 정보가 부족하다는 의미이므로 이 $s_t$의 점수를 높여 더 많이 탐색하도록 한다. 이를 각각 exploitation과 exploration이라고 한다. 따라서 node selection 과정을 정리하면 다음과 같다.
- Exploitation: 평균값이 높은 node를 선택
- Exploration: 표준편차가 높은 node를 선택
Node selection은 이 둘 사이의 trade-off를 고려하여 진행된다. 따라서 TreePolicy는 우리가 지금까지 공부했던 RL의 policy라기보다는 tree에서 node를 어떻게 결정할 것인가 하는 문제에 가깝다.
한편 DefaultPolicy는 실제 simulation을 진행하는 알고리즘으로, 여러 번 수행해야 하기 때문에 optimal하지 않더라도 빠른 policy $\pi$를 사용한다. 이를 통해 reward를 계산하고, backpropagation을 통해 각 node의 score를 업데이트한다. 아래 그림은 이 과정을 전부 나타낸다.
4. Trajectory Optimization
4.1. Terminology
Trajectory optimization에 앞서, 여기에서 사용되는 용어를 정리하고자 한다. 이 이론이 optimal control이라는 제어이론 분야에서 나왔기 때문에, 여기서는 state, action를 $s_t, a_t$로 나타내기보다는 $x_t, u_t$로 나타낸다. 그리고 reward $r(s_t, a_t)$보다는 cost $c(x_t, u_t)$로 나타낸다. (Reward와 cost는 반대의 개념이다.) 따라서 우리의 목적은 다음과 같이 나타낼 수 있다.
이를 미분을 통해 최적화하려고 하는데, 크게 두 가지 방법이 있다. 첫 번째는 shooting method로, action에 대해서만 optimization을 진행한다. 그리고 constraint를 식에 대입하였기에 constraint를 따로 가지지 않는다. 이는 앞으로 소개할 다른 방법에 비해 최적화가 불안정하며, second order derivative를 사용하는 것이 안정성에 도움이 된다.
두 번째는 collocation method로, state와 action 모두 optimization을 진행한다. 이때는 constraint를 따로 가지게 된다. 이 방법은 비교적 안정적이고, second order derivative를 사용하지 않아도 된다.
4.2. Linear Quadratic Regulator (LQR)
여기서는 trajectory optimization 중 가장 간단한 Linear Quadratic Regulator (LQR)에 대해 알아보자. LQR은 linear dynamics와 quadratic cost를 가정하고, 이를 최적화하는 방법으로, 이 경우에는 closed-form solution이 존재한다. Trajectory optimization 계열의 linear regression 문제를 푸는 것과 같다고 생각하면 된다.
결론부터 이야기하면 analytic solution은 다음과 같다.
\[\mathbf{u}_ t = \mathbf{K}_ t \mathbf{x}_ t + \mathbf{k}_ t\]즉, optimal action은 state에 대한 linear function이다. 따라서 state $\mathbf{x}_ t$가 주어지면 optimal action $\mathbf{u}_ t$를 계산할 수 있다. 그렇다면 $\mathbf{K}_ t, \mathbf{k}_ t$는 어떻게 계산할까? 이는 후술할 backward recursion 과정을 거쳐서 계산한다.
한편 optimal Q function(cost-to-go function) 및 value function은 다음과 같이 유도된다.
여기에서의 coefficient $\mathbf{Q}_ t, \mathbf{q}_ t, \mathbf{V}_ t, \mathbf{v}_ t$를 사용하면 $\mathbf{K}_ t, \mathbf{k}_ t$를 다음과 같이 계산할 수 있다.
우리가 알고 있는 것은 모델링한 dynamics $\mathbf{F}_ t, \mathbf{f}_ t$와 cost function $\mathbf{C}_ t, \mathbf{c}_ t$이다. 그리고 initial state $\mathbf{x}_ 1$을 얻을 수 있다. 그리고 계산을 통하여 final state의 Q function $\mathbf{Q}_ T, \mathbf{q}_ T$는 쉽게 얻을 수 있다. 이를 이용하여 backward recursion을 통해 $\mathbf{K}_ t, \mathbf{k}_ t$를 계산할 수 있다.
그리고 위와 같은 forward recursion을 통해 optimal action을 계산할 수 있다. 정리하면 다음과 같다.
- Backward recursion: $T \rightarrow 1$로 역으로 계산하여 gain $\mathbf{K}_ t, \mathbf{k}_ t$를 계산하는 과정
- Forward recursion: $1 \rightarrow T$로 순서대로 계산하여 action $\mathbf{u}_ t$를 계산하는 과정
지금까지는 deterministic dynamics 즉 $\mathbf{x}_ {t+1} = f(\mathbf{x}_ t, \mathbf{u}_ t)$를 가정했다. 그러나 stochastic dynamics 즉 $\mathbf{x}_ {t+1} \sim p(\mathbf{x}_ {t+1} \vert \mathbf{x}_ t, \mathbf{u}_ t)$인 경우에도 LQR을 적용할 수 있다. 이는 $p(\mathbf{x}_ t)$의 Gaussian symmetric property에 의해 가능하다.
4.3. Nonlinear Case: Iterative LQR
Dynamics, cost function이 nonlinear한 경우에 LQR을 적용하기 위해 Taylor expansion을 사용할 수 있다. 다만 이러한 근사의 경우 수렴성이 보장되지 않는다. 따라서 Iterative LQR이라는 방법을 사용한다. 이는 LQR을 반복적으로 적용하여 nonlinear한 경우에도 최적화를 진행하는 방법이다. 아래 그림은 이 과정을 나타낸다.
그러나 이러한 방법은 어쨌든 함수를 2차로 근사하는 것이기에 정확하지 않다. 위 그림이 그 이유를 잘 나타낸다. 따라서 improvement 정도인 $\alpha$를 도입하여 forward pass를 다음과 같이 수정할 수 있다.
\[\begin{aligned} \text{Original: } & \mathbf{u}_ t = \mathbf{K}_ t (\mathbf{x}_ t - \mathbf{\hat{x}}_ t) + \mathbf{k}_ t + \mathbf{\hat{u}}_ t \\ \text{Modified: } & \mathbf{u}_ t = \mathbf{K}_ t (\mathbf{x}_ t - \mathbf{\hat{x}}_ t) + \alpha \mathbf{k}_ t + \mathbf{\hat{u}}_ t \\ \end{aligned}\]그리고 실제로 improvement가 있는 $\alpha$를 탐색한다.
댓글 남기기